- Vison-Language-Action Model
- Remote Sensing Systems
- 2D to 3D face modeling
- Face Recognition using Super Resolution
- Autonomous Vehicle Technology
- 3D Skeleton Estimation
- Color Constancy
- Color Appearance Model
- Panoramic Imaging
- Image Dehazing
The Vision-Language-Action (VLA) model is an AI model that combines vision (image understanding), language (text understanding), and action (robot movement control). This model allows robots to interpret human instructions, understand the surrounding environment, and perform tasks based on visual and textual input.

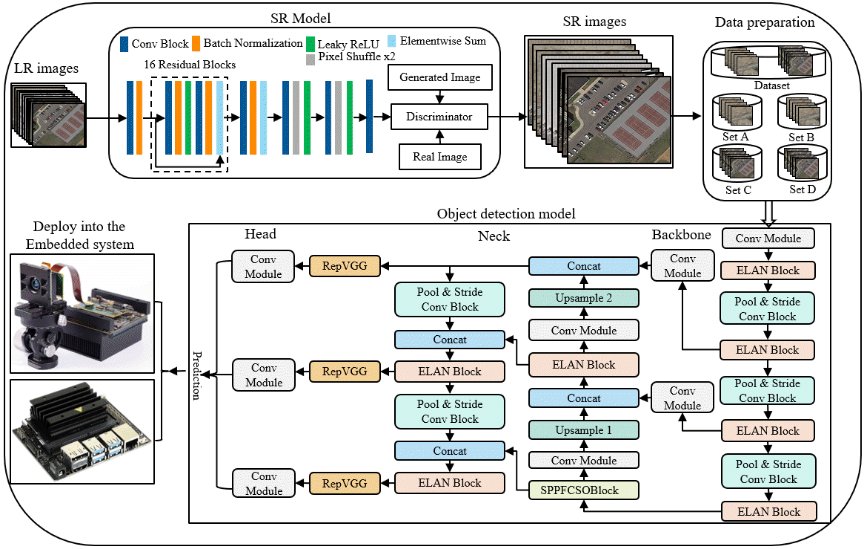
Remote sensing has advanced rapidly owing to the widespread use of image sensors, drones, and satellites to collect data. Object detection in remote sensing can be challenging because of small objects with low resolution (LR), complex scenes, and insufficient data to train the model. We propose X-transfer learning based on generative adversarial networks (GANs) that generate super-resolved data from LR for embedded systems.
This study aims to generate 3D face images from 2D images using artificial intelligence techniques. At this time, light sources, textures, and 3D information are used for face modeling.


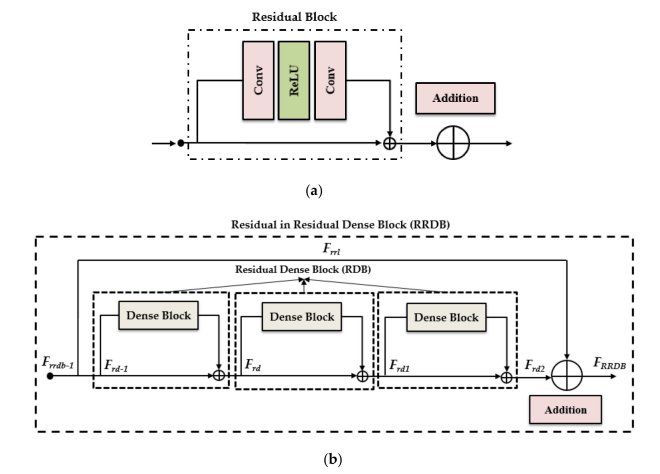
We propose a deep residual dense network (DRDN) for single image super- resolution. Based on human perceptual characteristics, the residual in residual dense block strategy (RRDB) is ex-ploited to implement various depths in network architectures. The proposed model exhibits a simple sequential structure comprising residual and dense blocks with skip connections. It im-proves the stability and computational complexity of the network, as well as the perceptual quality. We adopt a perceptual metric to learn and assess the quality of the reconstructed images.

For future autonomous cars, it is necessary to recognize various surrounding environments such as lanes, traffic lights, and vehicles. This paper presents a method of speed sign recognition from a single image in automatic driving assistance systems. The detection step with the proposed method emphasizes the color attributes in modified YUV color space because speed sign area is affected by color. The proposed method is further improved by extracting the digits from the highlighted circle region. A sequential cascade AdaBoost classifier is then used in the recognition step for real-time processing. Experimental results show the performance of the proposed algorithm is superior to that of conventional algorithms for various speed signs and real-world conditions.

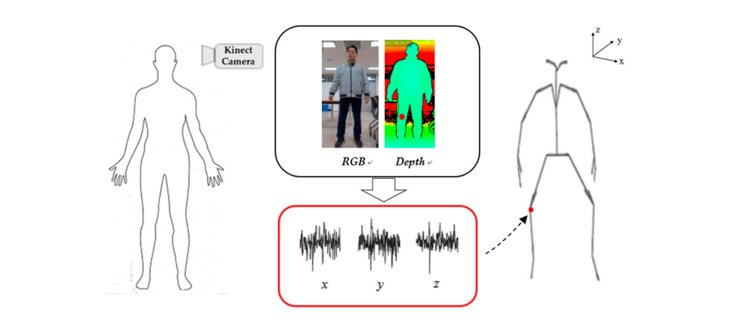
We propose a method for minimizing the noise of Kinect sensors for 3D skeleton estimation. Notably, it is difficult to effectively remove nonlinear noise when estimating 3D skeleton pos-ture; however, the proposed randomized unscented Kalman filter reduces the nonlinear tem-poral noise effectively through the state estimation process. The 3D skeleton data can then be es-timated at each step by iteratively passing the posterior state during the propagation and up-dating process.
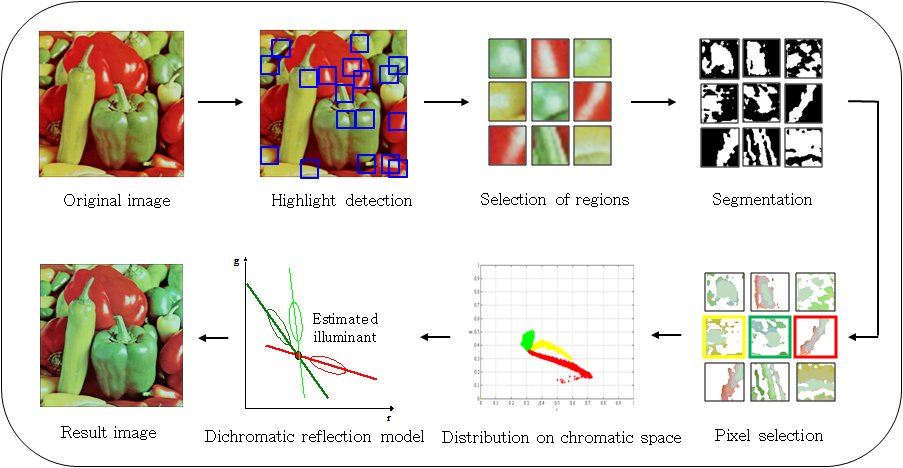
Under arbitrary illumination of an object, human eyes estimate the illuminant using integrated judgment; that is, the scene is corrected by the human visual system. However, artificial imaging systems are unable to recover images without access to the original illuminant, thus digital cameras include embedded color constancy algorithms. To solve this problem, we propose an illuminant compensation method using a camera noise analysis without segmentation.
Changes in the ambient conditions vary the sensitivities of the human visual system when watching a display, resulting in different perceptions under altered viewing conditions despite the same stimulus. Therefore, since a viewer s peripheral environment can be affected by artificial illumination, daylight, or fading light, algorithms are needed that can reproduce colors on a display under various types of ambient lightings as the viewing conditions are always changing.
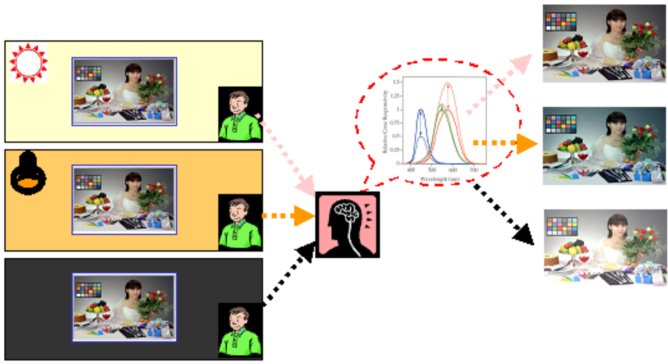
Image stitching has recently been attracting interest as an effective way of increasing the restricted field of view of a camera by combining a set of separate images into a single seamless image. This technique has already been widely applied to such areas as video compression, video indexing, image alignment, and panoramic videos, where panoramic technology in particular has been applied to lens falloff, exposure mismatches, and vignettes. As such, this paper focuses on how to derive clues from an image to implement panoramic technology.

Sunlight is transmitted to the observer through absorption, scattering, and re-emission in the atmosphere. Thus, in the case of inclement weather, images captured by a camera are degraded by haze that is dependent on the depth. In this study, the focus is a dehazing method for a single image.
